Over the past few posts, we built up to the Bellman optimality equations, which allows us to express the existence of an optimal policy that would maximize total rewards from a given environment, assuming the environment qualifies as a Markov Decision Process (MDP). Going forward, we will focus on algorithms that attempt to find policies that either satisfy the Bellman optimality equations or come close enough (i.e. local maximum) to meet our needs.
In this post, we introduce the concept of Dynamic Programming (DP) and use a few algorithms under this umbrella to solve a very simple reinforcement learning (RL) problem.
What is Dynamic Programming?
Dynamic Programming is a way of breaking down a complex problem into smaller subproblems in a recursive manner. It was developed in the 1950s by Richard Bellman (yes, the same person who gave us the Bellman equations previously discussed).
DP is not a single algorithm. Rather, it is a way of thinking about problems and designing algorithms. It has been successfully used for designing various algorithms in control theory, computer science, economics, and bioinformatics.
For our purposes, we are going to use the recursive nature of the Bellman equations to numerically approximate state values and find the optimal policy for a simple toy RL example.
1D Gridworld Environment
We’re going to move away from using the cartpole problem from our previous posts to introduce an even simpler example that helps demonstrate DP a little better. Imagine a simple board game that has five squares numbered 0 to 4. The left-most square (0) is a terminal state that offers no reward. The right-most square (4) is another terminal state that offers a reward of 1. States 1-3 offer no reward.
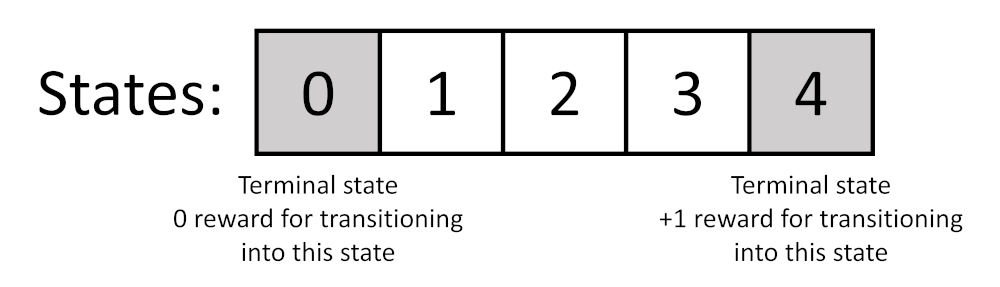
Our observation space is simply the number of the square our agent is in. Let’s say we always start in state 2, and the episode ends whenever the agent enters square 0 or 4. Our action space consists of two possibilities: move left and move right.
The twist to this environment is that whichever action you choose, you have an 80% chance of actually moving to that square. The other 20% of the time, you move one square in the opposite direction. For example, if you are in state 1 and your policy chooses the action “move right,” you have a 20% chance of ending up in square 0 (which would terminate the episode) and a 80% chance of ending up in square 2. This gives us a non-trivial transition dynamic to work with.
Intuitively, you will likely come to the conclusion that you should always move right anyway, and you should hopefully end up in square 4 to receive the only reward (with a small, unlucky chance of ultimately ending up in square 0). That being said, we want to use DP to prove this mathematically.
For simple RL problems like this, we can turn to four main algorithms under the DP umbrella that help us evaluate the dynamics and optimize a policy: policy evaluation, policy improvement, policy iteration, and value iteration. We’ll go through each of these in the rest of the post.
Policy Evaluation
Before we can begin iterating on a policy, we need a way to determine how good it is at solving the problem. For that, we turn to policy evaluation. Let’s set our discount factor to γ=0.9 and start with a simple random policy of 50% move left and 50% move right.
Because the system dynamics are completely known to us, we can plug in the values directly into the Bellman equation for vπ.
\(v_{\pi}(s) = \sum\limits_{a} \pi(a|s) \sum\limits_{s’,r} p(s’, r | s, a) \left[ r + \gamma v_{\pi}(s’) \right]\)
In order to have something to start with, we initially assume all states have a discounted return of 0. In other words, v(s)=0 for all states initially. Using that, let’s solve the recursive Bellman equation for each state.
States 0 and 4 themselves have a return of 0, as they are considered terminal states.
Let’s work through the value of state 1 (with the assumption that the states next to it have the value v(s)=0).
Move left (π=0.5):
- p(s’=0|s=1, a=left) = 80%, so: 0.8 ⋅ (r + γ ⋅ v(s’=2)) = 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=2|s=1, a=left) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
Move right (π=0.5):
- p(s’=2|s=1, a=right) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=0|s=1, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
To calculate v(s=1), we combine these in the state Bellman equation:
v(1) = 0.5 ⋅ 0 + 0.5 ⋅ 0 = 0
Note that this is not correct (yet). We know intuitively that there’s still a chance to reach state 4 from state 1, so v(1)=0 is only an estimate at this particular iteration. We will apply DP in a moment so that v(1) (along with the values of the other states) start to converge on their true values.
State 2 has a similar calculation. State 3 is a little more interesting, as the agent can move into state 4 to gain a reward:
State 3, move left (π=0.5):
- p(s’=2|s=3, a=left) = 80%, so: 0.8 ⋅ (r + γ ⋅ v(s’=2)) = 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=4|s=3, a=left) = 20%, so: 0.2 ⋅ (1 + 0.9 ⋅ 0) = 0.2
State 3, move right (π=0.5):
- p(s’=4|s=3, a=right) = 80%, so: 0.8 ⋅ (1 + 0.9 ⋅ 0) = 0.8
- p(s’=2|s=3, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
To calculate v(s=3), we combine these in the state Bellman equation:
v(3) = 0.5 ⋅ 0.2 + 0.5 ⋅ 0.8 = 0.5
At this point, it looks like only v(3) has an estimated discounted return of 0.5. The other states show a return of 0.
To apply our dynamic programming technique, we simply run this again, using the newly calculated values of v(s) for all state transitions (in place of v(s’)). This is known as a synchronous update: all states use the values from the previous iteration. In other words, for iteration k, our new estimates become:
\(v_{k+1}(s) = \sum\limits_{a} \pi(a|s) \sum\limits_{s’,r} p(s’, r | s, a) \left[ r + \gamma v_k(s’) \right]\)
While v(0), v(1), and v(2) were 0 for iteration k=1, v(3) is now 0.5. That means our evaluations of v(2) and v(3) are now different.
For iteration k=2, v(0), v(1), and v(4) remain the same. Let’s see how v(2) and v(3) change:
State 2, move left (π=0.5):
- p(s’=1|s=2, a=left) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=3|s=2, a=left) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0.5) = 0.09
State 2, move right (π=0.5):
- p(s’=3|s=2, a=right) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0.5) = 0.36
- p(s’=1|s=2, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
v(2) = 0.5 ⋅ (0 + 0.09) + 0.5 ⋅ (0.36 + 0) = 0.225
State 3, move left (π=0.5):
- p(s’=2|s=3, a=left) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=4|s=3, a=left) = 20%, so: 0.2 ⋅ (1 + 0.9 ⋅ 0) = 0.2
State 3, move right (π=0.5):
- p(s’=4|s=3, a=right) = 80%, so: 0.8 ⋅ (1 + 0.9 ⋅ 0) = 0.8
- p(s’=2|s=3, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
v(3) = 0.5 ⋅ 0.2 + 0.5 ⋅ 0.8 = 0.5
Repeat this process for a third iteration. You can fill out a table like this to see how the values propagate out from the only reward (transition to state 4).
| State | v(s) Iteration 1 | v(s) Iteration 2 | v(s) Iteration 3 |
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0.101 |
| 2 | 0 | 0.225 | 0.225 |
| 3 | 0.5 | 0.5 | 0.601 |
| 4 | 0 | 0 | 0 |
While this process could continue forever, you would ultimately want to stop the iterations once the changes between the updates became small enough (i.e. under some predetermined threshold). When the values begin to settle, we say that they converge for recursive algorithms like this.
Remember that we are evaluating the random policy (choosing left or right with equal likelihood). Once policy evaluation has converged, we have a good estimate of how well our current policy is performing. Now we can use those estimates to create a better policy.
Policy Improvement
With our new estimates of the state values (from the initial policy), we can then update our policy to choose better actions (i.e. ones that promise better discounted returns). Intuitively, the new policy should simply choose the action that maximizes the value in the next state. This is known as the greedy policy.
Mathematically, this policy update (the new policy being π’) looks like the following:
\(\pi'(s) = \arg\max\limits_{a} \sum_{s’,r} p(s’, r | s, a) \left[ r + \gamma v_{\pi}(s’) \right] = \arg\max\limits_{a} q_{\pi} \left( s, a \right)\)
These look a lot like the Bellman optimality equations from the previous post. The new greedy policy, π’, is guaranteed to be at least as good as the previous policy. Also note that the greedy policy is deterministic (always choosing one action) rather than a probability distribution, as we discussed in part 5.
For our simple 1D gridworld problem, one policy update is all it takes to find the optimal policy. In every case, the state to the right of the current state has a higher value, so the agent should simply choose to always move right (i.e. π(a=right|s)=1.0).
However, that’s not always the case. You might need to reevaluate the policy before making another update.
Policy Iteration
Once a policy has been improved to something better (π’), you can then perform another policy evaluation step to estimate the state values under this new policy (vπ’(s)). You can use the recursive policy evaluation algorithm we described to accomplish this.
With the new state values calculated, you can then perform another policy improvement step, and so on, ultimately converging to the optimal policy:
π0 → evaluate to get vπ0 → improve to get π1 → evaluate to get vπ1 → improve to get π2 → …
This will eventually converge on the optimal policy, π*, along with the optimal state values, v*.
Note that each policy evaluation step requires running the iterative process to full convergence before moving on to the improvement step. For our toy example, this is trivial. This becomes computationally expensive for large state spaces or even intractable for continuous spaces.
We can speed up these iterations by performing value iteration.
Value Iteration
Value iteration combines policy evaluation and policy improvement into one step. Only one sweep of each is performed in a single update. Mathematically, this update can be expressed as follows:
\(v_{k+1}(s) = \max\limits_{a} \sum\limits_{s’,r} p(s’, r | s, a) \left[ r + \gamma v_k(s’) \right]\)
Instead of using the expectation equation (i.e. the recursive Bellman equation) to estimate the value (discounted return) of each state, we are using the Bellman optimality equation to perform an update. In other words, instead of weighting actions by policy probabilities, we simply take the action with the max value at each state.
Let’s see how this works for our 1D gridworld example. We start with v(s)=0 for all states, just as we did in policy evaluation. Note that we do not need an initial policy, as we assume the policy will ultimately choose the action with the maximum value.
Let’s work through the value of state 1 (with the assumption that the states next to it have the value v(s)=0).
Move left:
- p(s’=0|s=1, a=left) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=2|s=1, a=left) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
Move right:
- p(s’=2|s=1, a=right) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=0|s=1, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
To calculate v(s=1), we choose the action with the maximum value (rather than simply weighting the values by their action probabilities, as we did in the policy evaluation method):
v(1) = max(0, 0) = 0
State 2 has a similar calculation. State 3 is different, and you can see how value iteration is different than policy evaluation from this update alone:
State 3, move left:
- p(s’=2|s=3, a=left) = 80%, so: 0.8 ⋅ (0 + 0.9 ⋅ 0) = 0
- p(s’=4|s=3, a=left) = 20%, so: 0.2 ⋅ (1 + 0.9 ⋅ 0) = 0.2
State 3, move right:
- p(s’=4|s=3, a=right) = 80%, so: 0.8 ⋅ (1 + 0.9 ⋅ 0) = 0.8
- p(s’=2|s=3, a=right) = 20%, so: 0.2 ⋅ (0 + 0.9 ⋅ 0) = 0
To calculate v(s=3), we choose the maximum:
v(3) = max(0.2, 0.8) = 0.8
That concludes the first iteration of value iteration. You would then use these values to perform another iteration, just like you did in policy evaluation, but choosing the maximum action value (instead of weighting by the policy probabilities).
Here is a table showing how the state values change after three iterations:
| State | v(s) Iteration 1 | v(s) Iteration 2 | v(s) Iteration 3 |
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0.415 |
| 2 | 0 | 0.576 | 0.576 |
| 3 | 0.8 | 0.8 | 0.904 |
| 4 | 0 | 0 | 0 |
Notice that the values are higher in value iteration than in policy evaluation after only a few updates. We assume that the optimal policy will always greedily choose the action that results in the most value. We effectively roll that assumption into our value updates so that both policy and value estimates converge more quickly.
Generalized Policy Iteration
If you look back at the DP methods we just covered, you’ll see a general pattern of iterating on the evaluation (figuring out how good the current policy is) and improving the policy. Note that you can also combine these into one step, as we did with value iteration.
This general framework of iterating on evaluation and improvement is known as generalized policy iteration (GPI). As long as you keep alternating between some form of evaluation and some form of improvement, the two processes will eventually converge to the optimal value function and optimal policy.
GPI shows up in most RL algorithms we’ll look at in this series. It shows up in Monte Carlo and TD learning, where the evaluation step uses sampled experience rather than known transition probabilities. While the individual algorithms might look different on the surface, the underlying evaluate-then-improve loop concept remains the same.
Conclusion
You should understand that the DP methods we detailed in this post only work with the assumption that the model dynamics are known (i.e. we know the transition probabilities to next states). They are also only feasible for small state spaces. Most real-life RL problems you encounter will meet neither of those criteria.
In the next post, we will explore Monte Carlo (MC) methods that sample from episodes to approximate state and action values. They are model-free algorithms, meaning they estimate value functions directly from sampled experience rather than requiring knowledge of the environment’s transition probabilities. In other words, instead of knowing p(s’|s,a) ahead of time (as we did in this post), a model-free algorithm learns purely by interacting with the environment and observing what happens.
Feel free to use the comment section to ask questions or point out any errors you might find!