One of the biggest complaints about many home assistants (like the Amazon Echo) is the inability to create custom wake words. Sure, you can select from a list of pre-existing wake words, but to create your own is quite a technical challenge. Sometimes, it might be fun to say something other than “Alexa” or “OK Google.”
I want to create a multi-part series on how you might go about creating custom wake words (also known as a “hotword”). These tutorials will show you how to collect voice samples and train a simple machine learning model (neural network) to use on any number of devices, including single board computers (e.g. Raspberry Pi) and microcontrollers (e.g. Arduino).
This first tutorial will demonstrate one possible way to collect voice samples necessary for training your model. If you would like to see me discuss data collection and why I’m doing this project, see this video:
Table of Contents
Why You Need to Capture Data for Your Custom Wake Word
Unfortunately, you can’t just say a word a couple of times and train a neural network to recognize that word. Computers are still not quite as capable as toddlers.
Even if you said a word 100 times, the neural network would likely learn features of your voice rather than the word itself. After that, every time you said something even remotely close to the wake word, the model would label it as the wake word.
To remedy this, we need lots of different types of people with different types of voices saying the same word (and with different inflections). With hundreds or thousands of different training examples, the neural network will hopefully learn the features that uniquely make up that word rather than your particular voice.
Companies that make voice assistants have their own methods of capturing voice samples. For example, Google scrapes millions of YouTube videos to create audio training sets for sounds and voices. Here is an example of one such set you can use in your training. Note that these are “human-labeled,” meaning Google likely paid lots of people to listen to lots of audio clips and assign a label to each one.
Another way to collect voice data is by crowd-sourcing. We can do that by creating a web page that people can volunteer to submit their own audio samples.
Google Speech Commands Dataset
For the TinyML research project as part of the TensorFlow Lite library, Pete Warden created the Speech Commands Dataset, which you can download here.
Pete collected this data by asking volunteers to visit a web page, which he designed to walk users through submitting voice samples. You can visit that page here.
The Google Speech Commands dataset was used to train a neural network to recognize simple words, such as “yes,” “no,” “up,” “down,” and so on. The model was simple enough to be deployed on a microcontroller so that it could recognize one or more of these words.
You can learn more about the Google Speech Commands dataset here. Pete Warden has released code for this page here.
simple-recorderjs
Had I known about the Pete’s source code, I probably would have used that. However, I ended up going down a slightly different route to crowd source my wake word dataset.
I came across this open source project, which adds an audio recording and playback feature to web pages. Since I am not much of a web developer, I got my friend, Andrew, to help me modify that project to my needs.
Custom Speech Data Collection Page
The code Andrew and I came up with can be found in this GitHub repository. Specifically, it is saved in the “botwords” directory.
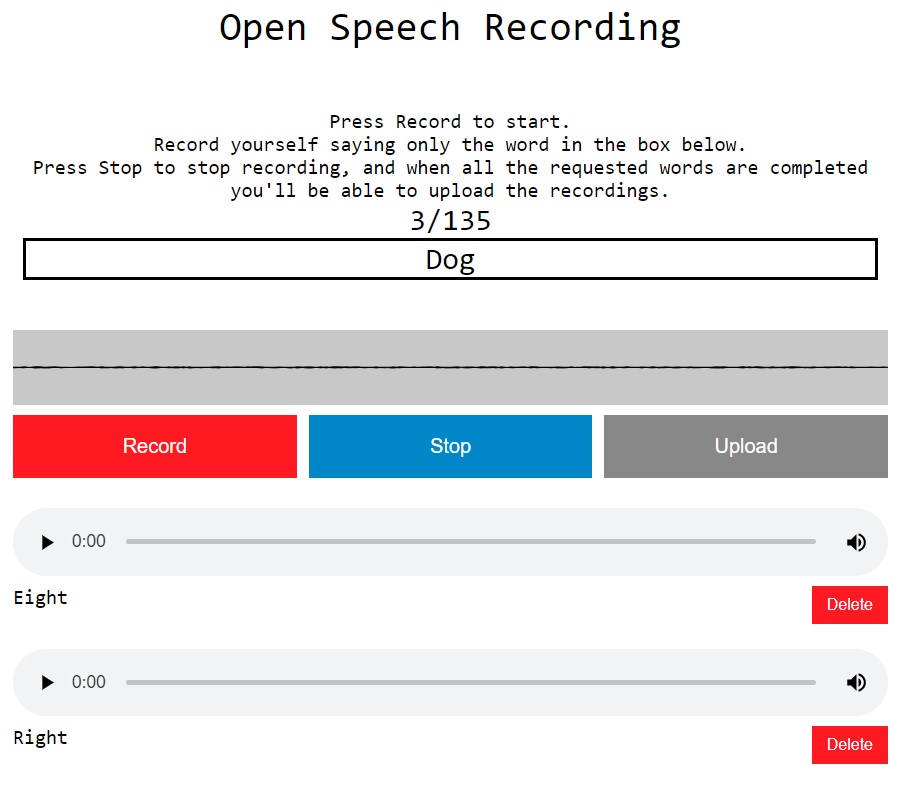
The botwords page is hosted on my server as a standalone page. It is very simple HTML and does not rely on any other frameworks (such as WordPress). It gives an overview of the projects my collaborators and I are working on and instructions on how to submit your voice.
A user can press the “Record” button under each word to record their sample. Once recorded, a playback bar will appear, which allows users to preview their recording. If satisfied, they can click “Upload to server,” which will save the .wav file on my server. Users are encourages to create multiple recordings with different inflections for each wake word or phrase.
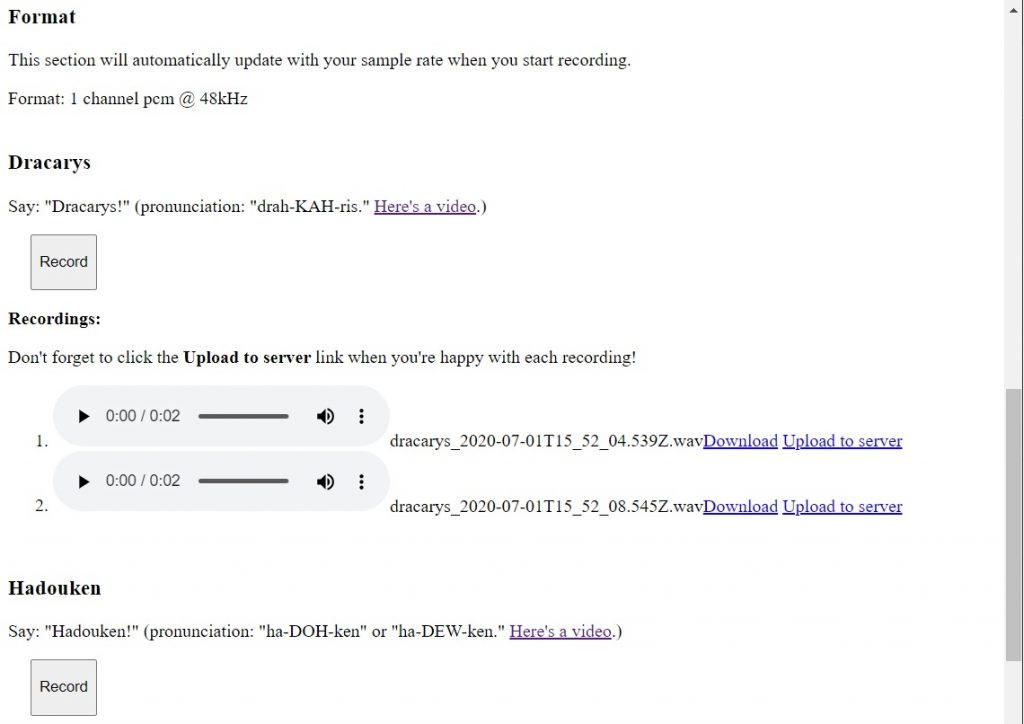
To use the page, simply drop the botwords folder into your public_html folder on your server. It will then be hosted at <your_website>/botwords. Feel free to change the code in index.html and app.js to perform whatever actions you want. You can change the slug by changing the directory name. For example, if you rename the botwords directory to myproject, the URL becomes <your_website>/myproject.
From there, tell all your friends and get people to submit speech samples. I do not recommend leaving the page up indefinitely, as your server could easily become overloaded, depending on how popular you are.
When you’re done running your “speech crowd sourcing campaign,” log into your server and download the .wav files, which should be located in the project directory (botwords for me).
Modifying the Code
If you want to use the botwords code for your own project, you should not need to modify app.js (unless you want to change how recording is done or to increase/decrease the recording time).
The part you need to worry about is how the recordButton objects work in index.html. Here is one example:
<!-- Section: Hadouken -->
<br>
<h3>Hadouken</h3>
<p>Say: "Hadouken!" (pronunciation: "ha-DOH-ken" or "ha-DEW-ken." <a href="https://www.youtube.com/watch?v=7jgdycXQv80">Here's a video</a>.)</p>
<button class="recordButton" id="hadouken" style="height:50px; margin-left:20px;">Record</button>
<p><strong>Recordings:</strong></p>
<ol id="hadoukenList"></ol>Notice that we assigned the button to class “recordButton” and gave it a unique ID that told us something about the wake word we want to record. That ID string is prepended to the front of the .wav filename, and it should be the same string found in the <ol> list (prepended to the ID string, such as “hadoukenList”). The JavaScript code will look for this list ID name when attaching playback objects.
So, if you wanted to record “hello,” you would need:
<button class="recordButton" id="hello" style="height:50px; margin-left:20px;">Record</button>
<p><strong>Recordings:</strong></p>
<ol id="helloList"></ol>Collaboration
For my personal project, I would like to get a video game controller to respond to the Street Fighter II phrase “hadouken.” This might seem frivolous (because, well, it is), but I’m hoping I can use it as a way to develop a series of tools and tutorials to help people train their own wake words.
Additionally, I am collaborating with Jorvon Moss (@Odd_Jayy), who is building a dragon companion bot along with with Alex Glow (@glowascii), who is modifying her owl bot and building a new fennec fox bot. Both of these amazing makers are hoping to have their robotic pets respond to a handful of spoken words.
Conclusion
Much has been written about automatic speech recognition (ASR), and many tools already exist in our daily lives that we can interact with using our voices (e.g. asking Alexa a question). These ASR systems often require huge systems to process full speech.
I would like to find ways to make machine learning simpler by bringing it to the edge. What kinds of fun things would you make if your device could only respond to 2 different spoken words? The advantage is that it does not require an Internet connection or a full computer to operate.
In the process, I hope to make machine learning more accessible to makers, engineers, and programmers who might not have a background in it.